This blog post supports an ignite talk given at the Europeana AGM, Riga, November 2016 (slides)
Quick link: install Chrome extension demonstrator
Having worked for two years at Europeana, but now working for Imperial War Museums, a data provider, I wanted to ask the question:
What can data providers get back from Europeana, both for themselves and for their users?
When we provide data to Europeana, do we think what data we can get back? What others have provided that would be of interest to our own users? Individual objects often have rich information but are often dead ends. To me I want to know more. What else is around here? What happened on the same day? Did this artist paint other paintings? Where can I see all these things?
In the context of the Imperial War Museums’ (IWM) collections there are some fascinating possibilities given the geographic coverage of Europeana, extending the corpus of content relating to major conflicts. This could range from official documents, maps and photographs of battles from both sides, through to personal artefacts that relate to the service of an individual.
What are the possibilities? What approaches can we adopt? What tools could help?
Europeana Labs has an Apps showcase that aims to highlight the ways that Europeana content and the API have been used. It is clear that many stand-alone discovery tools exist, but from the perspective of data providers there are just a handful of examples, typically where a search box is provided alongside the collections, or there’s is an option within search results that allows a user to also explore Europeana.
Whilst such signposting appears useful, I wonder what actual use it gets, and what value it brings? At an individual record level I’m not aware of any sites (though I stand to be corrected!) where there is a link to the Europeana record, or indeed in most cases even any acknowledgement that the item is in Europeana. And yet this is where I see there being a great opportunity to tap into the data and tools that Europeana provides.
To explore this idea I have hacked a very quick demonstrator in the form of a Chrome browser extension. The concept is very simple – running on collections sites (currently a small sample) it detects if the item is in Europeana, retrieves the metadata through the Europeana API, and then based on recorded metadata for time, place and people (and broader concepts) it allows the user to display matches from across Europeana.

Taking this IWM image of General Oskar von Hutier, the Commander of German Eight Army, after the capture of Riga on 3rd September 1917, not just the title but crucially the metadata tells us it was created on 1917-09-03 in Riga, Latvia and shows Hutier, Oskar Von.
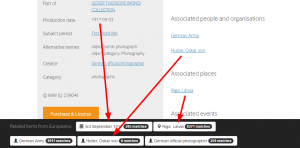
Through the Europeana API we can then fetch the matches for each of these, and using some quite simple code and basic design give the user the ability to view them. So in this case they can find (at the time of writing) 285 things also relating to 3rd September 1917 (including many newspapers from across Europe), 8,271 items close to the centre of Riga, and 8 items, including photographs and articles, about Oskar von Hutier.
It’s as simple as that, but hopefully opens up a world of possibilities for cross-collection discovery!
If you want to see for yourself, install the Chrome browser extension and try some of the following links:
Imperial War Museums
- 110 images relating to Riga
- all images taken ‘on this day in history‘ (open each image and click on the link to the IWM record)
- Battlefield panorama, Loos-en-Gohelle, Pas-de-Calais, France, 13th August 1916
- map showing the scale of a crater in relation to German and British trenches, 1st July 1916 (first day of the Battle of the Somme)
- British naval mine washed up at Sizewell, Suffolk, two scouts and two men stand behind it, 9 November 1914
- French Donnet flying boat (Type DD) on the water in Salonika, 9 November 1916
- Painting of Menin Gate Watering Point, Ypres, by David Baxter
Other collections
- Partita cambiata / R. Jonni – poster with only high level metadata from 1914-18.it
- 5° Reggimento Fanteria. Brigata Aosta – a postcard with high level metadata from 1914-18.it
- more coming soon …
What next?
This has been implemented very simply and very quickly. Using better linked data approaches, entity recognition, similarity algorithms, and no doubt a whole host of other clever things, I’m sure it could be much improved. It could run as a browser extension, but equally the idea could be applied on specific sites so all users see results. It could also be adapted specific themes, for example to limit the corpus from which results are retrieved to one subject such as 1914-18, or art.
Some background
It is worth mentioning that some similar tools do already exist, most notably the Eexcess Chrome extension. However, the aim here is to provide a demonstration of a lightweight tool focused on collection objects.
Some technical details
What about collections items that are not in Europeana? The idea can be extended by extracting concepts through other methods, either present in the page itself (as long as they are structured and identifiable) or through a collection’s own API. The tool also does a little bit of its own interpretation of data to enhance results, something that could be easily expanded. An example is that if no date is present it parses the title and description to extract any date that can be detected. Another example is that the Imperial War Museums collections contain placenames but not geotags, so it looks up the placenames using pre-fetched results from the Google Maps API.
What are the challenges?
The discovery can only be as good as the metadata. Put succinctly, the better the metadata the more focused the results and the less noise. From the object point of view, if something has only been recorded as a photograph taken in Paris, then all the user can expect to get back is photographs, and other things from Paris. But let’s assume the item has been catalogued in detail, for example it’s a photograph of the Ancien Couvent de l’Abbaye aux Bois, at 16 Rue de Sèvres by Eugene Atget taken in 1908. You’d expect some great results with all the other items showing this building or by Eugene Atget, or created in 1908. But to achieve that they will all need to have that same metadata, or at least the search methods need to take account of differences in format, spelling, and language. My experience is that this varies extensively between providers, but that’s another reason to strive to improve what we all contribute.
Similarly there are some basic technical issues that mean some providers items are difficult to work with. One example is where their collections items are presented with urls that don’t match the ones provided to Europeana. Sometimes this can be coded for, but that just makes the tool harder to manage and less scalable. Sometimes it’s simply impossible (perhaps the providers could put unique Europeana IDs in their pages?)
Finally, by its very nature a browser plugin is going to be of very limited use as it relies on people discovering it, having the right technology, and installing it. The same code could easily be embedded by providers on their own collections sites, or better still the principle could be taken and developed in a far more integrated way.
Sneak preview of blog post and Chrome extension demonstrator that I’ll be talking about at @europeanaeu #agm2016 https://t.co/6IXAfo5z7S
Here’s the blog post supporting my @europeanaeu #agm2016 ignite presentation https://t.co/rcJg1DYJBh https://t.co/jrkjeSl2gR
RT @jamesinealing: Here’s the blog post supporting my @europeanaeu #agm2016 ignite presentation https://t.co/rcJg1DYJBh https://t.co/jrkjeS…
RT @jamesinealing: Here’s the blog post supporting my @europeanaeu #agm2016 ignite presentation https://t.co/rcJg1DYJBh https://t.co/jrkjeS…
RT @jamesinealing: Here’s the blog post supporting my @europeanaeu #agm2016 ignite presentation https://t.co/rcJg1DYJBh https://t.co/jrkjeS…
RT @jamesinealing: Here’s the blog post supporting my @europeanaeu #agm2016 ignite presentation https://t.co/rcJg1DYJBh https://t.co/jrkjeS…
RT @jamesinealing: Here’s the blog post supporting my @europeanaeu #agm2016 ignite presentation https://t.co/rcJg1DYJBh https://t.co/jrkjeS…