A simple but powerful tool to bulk extract media and associated metadata using the Science Museum API
In February 2017 the Science Museum’s Digital Lab ran #SMHack, a two day event which posed the question “What would you do if the Science Museum and its data were your creative playground for 2 days?”
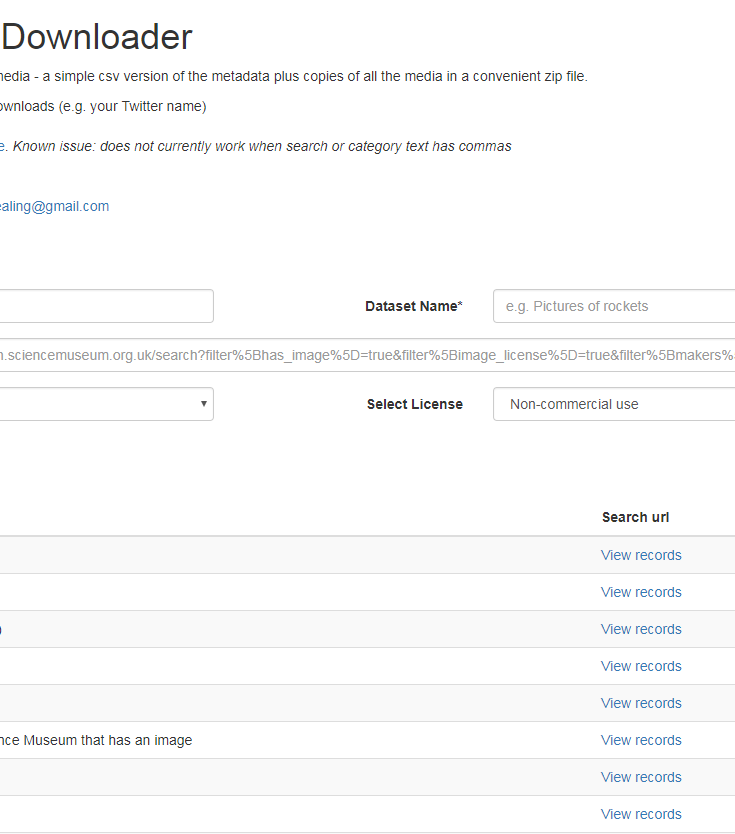
From my experience supporting developers and creatives at similar events for Europeana I knew that the last things people want are technical barriers to getting the content they need, so I built on some code I had written for Europeana and created a simple interface. The key was not building a whole new search interface so I took the lazy (I say smart!) move of powering the query by inviting users to paste in the url after searching the collections search front end and then translating that into the API calls which handled both the query and the pagination that allowed for the bulk upload. After that, the tool downloads all the media derivatives (currently only for images) meanwhile building both a csv and json file to contain pertinent record metadata. At the very end it zips it all up and offers users a link to download it.