


Latest thoughts and experiments
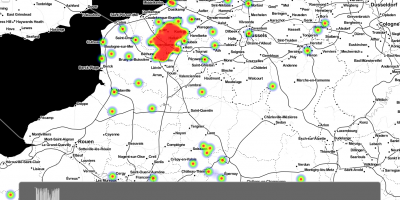
A Street Near you – a case study in linking disparate datasets
Note – this is a rather hurried post to accompany my talk for the Science Museum public webinar on Wikidata and cultural heritage collections, part of the Heritage Connector project. It will be tidied up and links and images added over the coming days, but the core details are here! Presentation Read more …
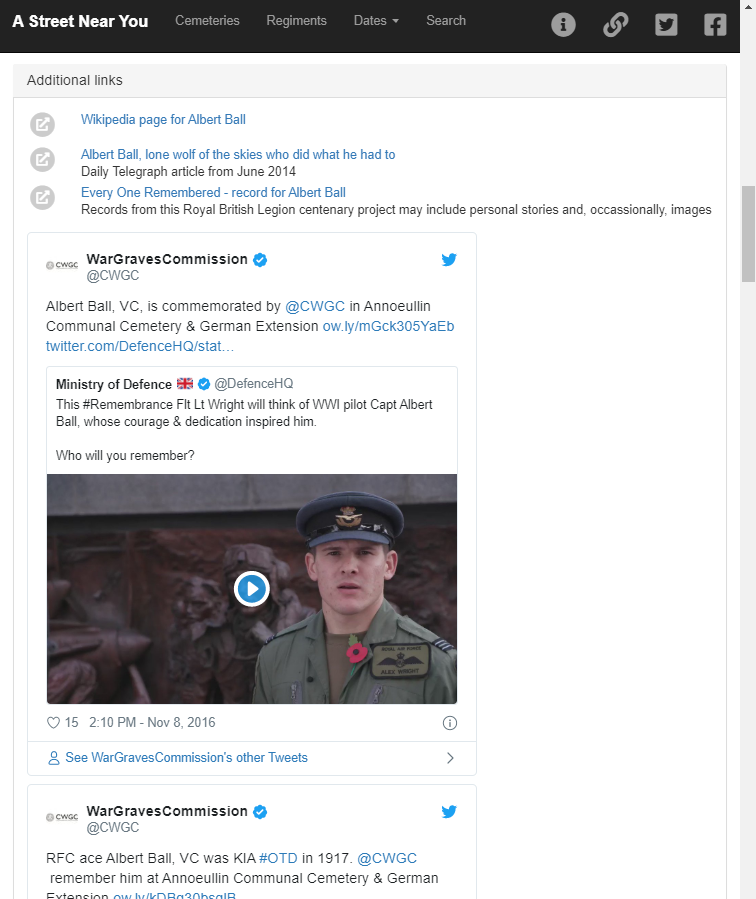
Collecting and displaying contextual tweets for cultural heritage records
This post outlines a really simple way to gather tweets that relate to cultural heritage objects/records and shows how displaying them on the record pages can add value for users. Whilst only covering Twitter it could be applied to many social media platforms. It’s really quick and simple, using freely Read more …
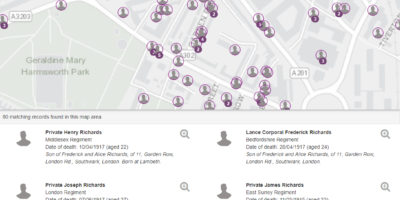
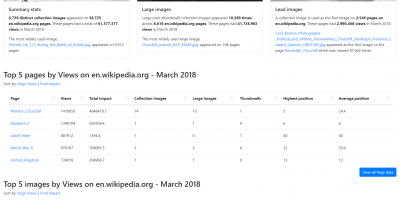
My ‘viral’ moment – A Street Near You & the power of linking First World War data sources
A Street Near You started as an idea to demonstrate the potential of combining and enhancing large datasets focused on the First World War. Three weeks after its launch on 9 November it had: had 435,000 unique visitors been tweeted over 3,600 times with links to the site (one tweet Read more …
Representing the ‘average’ soldier from the First World War
How this came about Back in January 2018 I posted some of the image-based work I had been doing on Imperial War Museum’s Bond of Sacrifice collection. As part of this I sent out a tweet with a simple animation. As a result I got chatting to Giuseppe Sollazzo (@puntofisso) Read more …
Linking collections – aiding discovery through Europeana
This blog post supports an ignite talk given at the Europeana AGM, Riga, November 2016 (slides) Quick link: install Chrome extension demonstrator Having worked for two years at Europeana, but now working for Imperial War Museums, a data provider, I wanted to ask the question: What can data providers get back from Europeana, Read more …
Europeana plugins and embedding tools – test page
This post is a test page for various independently developed WordPress plugins that include Europeana driven functionality. 1. CHContext plugin Sidebar results (see right) displayed based on the page tags (‘kitten’) using the CHContext plugin 2. DPLA & Europeana search plugin Sidebar search box widgets (see right) created with DPLA & Europeana Read more …